Architecture Overview
Advanced Audio Tokenization
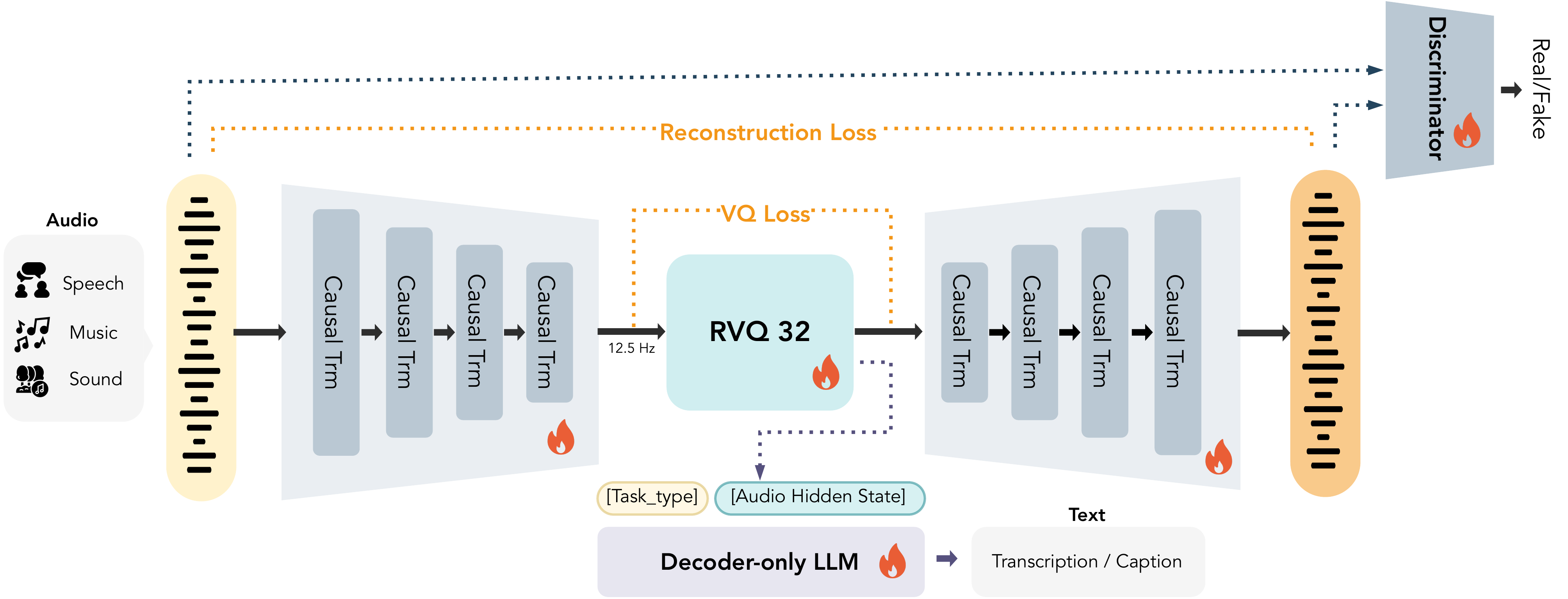
MOSS-TTS utilizes a unified Audio Tokenizer based on the Causal Audio Tokenizer (Cat) architecture. This 1.6-billion-parameter model compresses 24kHz raw audio into a remarkable 12.5Hz frame rate using a 32-layer Residual Vector Quantizer (RVQ), supporting variable bitrates from 0.125kbps to 4kbps.
Trained on 3 million hours of diverse data (speech, sound effects, and music), the model achieves state-of-the-art reconstruction quality among open-source audio tokenizers.